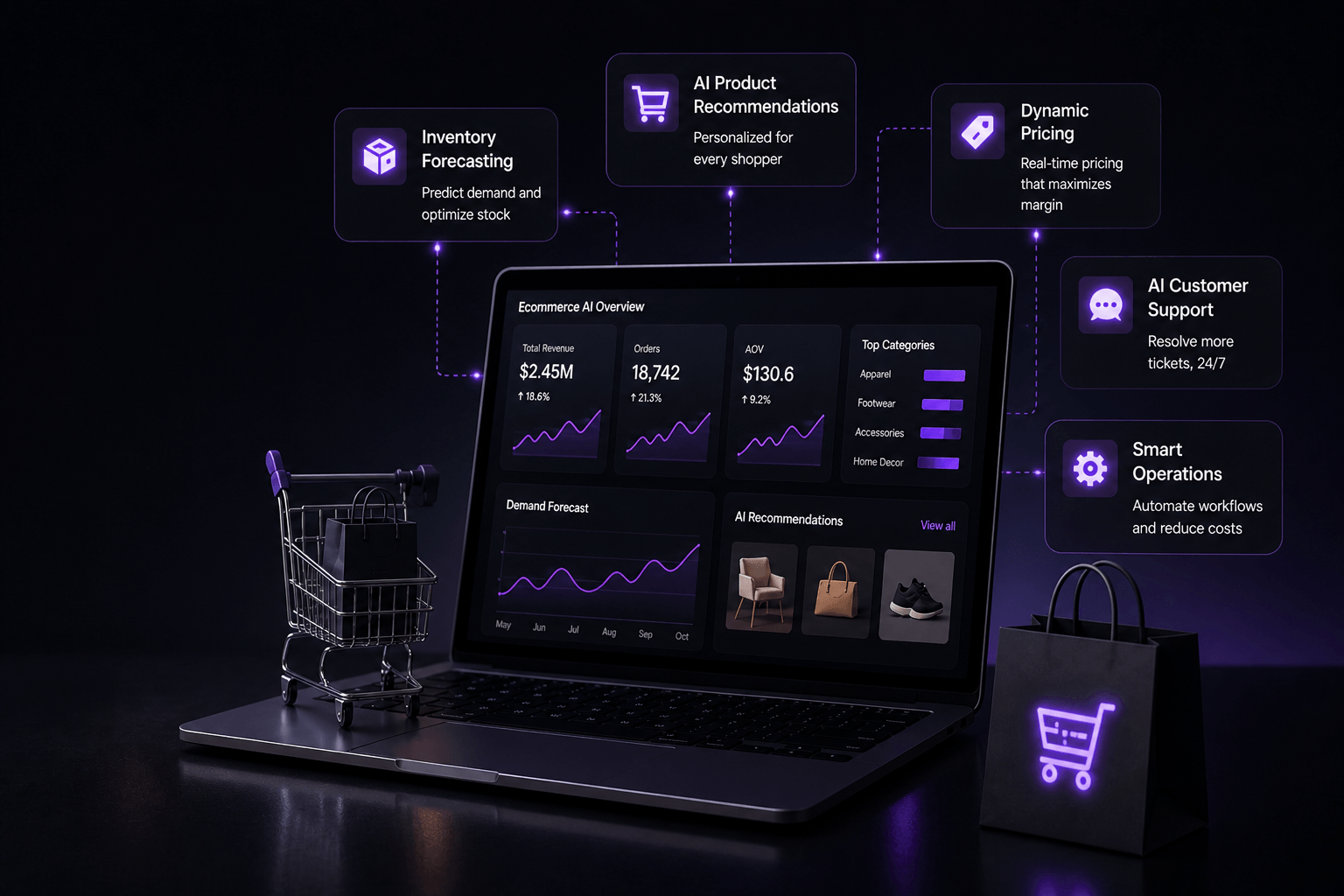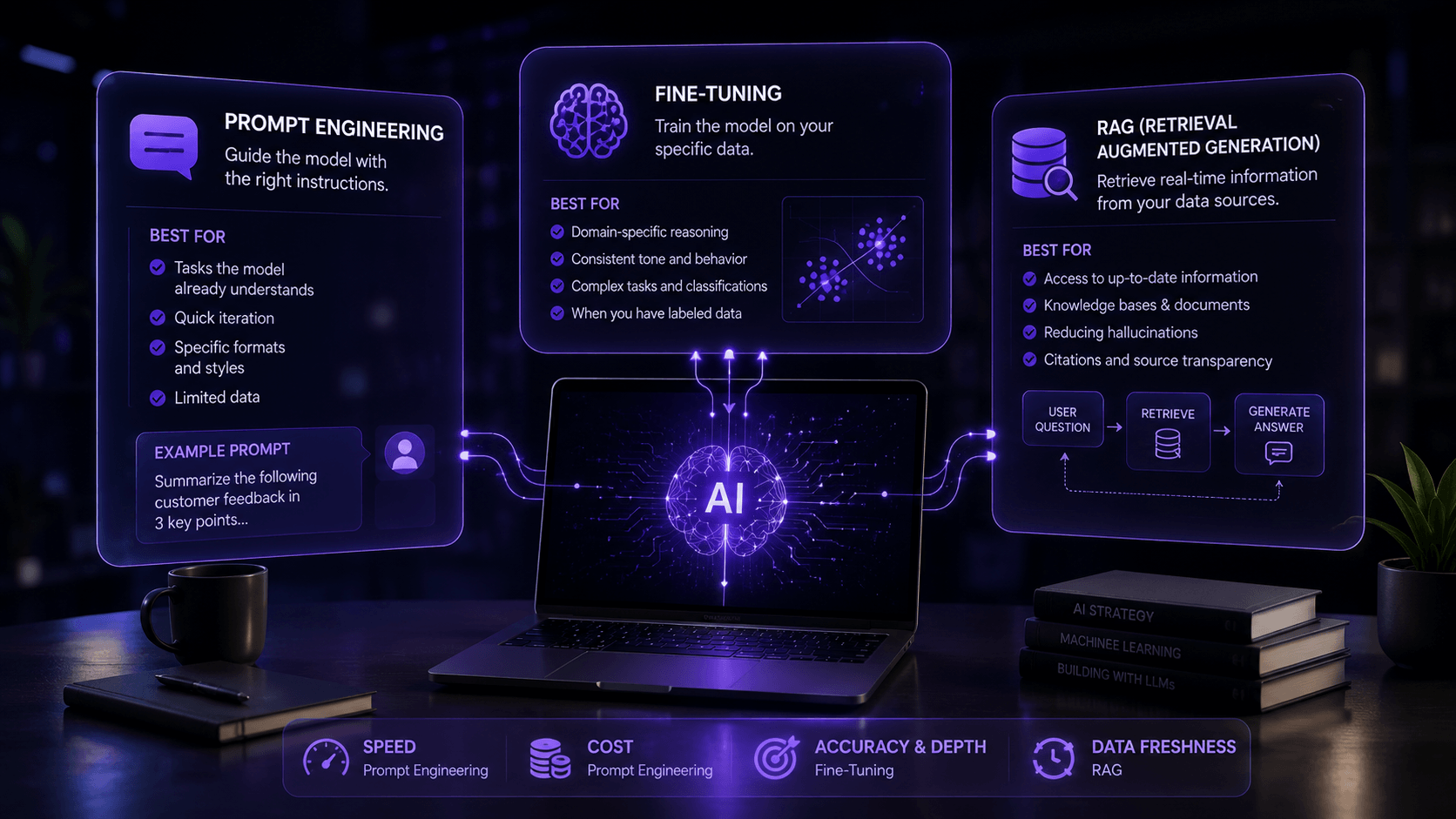



I was talking to someone the other day and they asked me ifthey should just try out some prompts with GPT or ifthey should build their own custom model. I think this is not the question to ask.
What people do not tell you when you are trying to figure out how to use Artificial Intelligence for your business is that you are not choosing between bad options. You are choosing between three different tools that solve completely different problems. Most people pick the wrong tool because they are focused on what sounds impressive instead ofwhat actually solves the problem.
I am talking about prompt engineering and fine-tuning and RAG. These are three ways to make Large Language Models do what you need. Each one is brilliant for certain situations but a total disaster for others.
The frustrating thing is that I watch companies bet their Artificial Intelligence strategy on the wrong approach. Not because they are incompetent but because nobody explained what these things actually do in plain terms. Everyone just uses jargon and assumes you know when to use what. So here is the breakdown ofprompt engineering vs fine-tuning vs RAG. No fluff. No saying it depends on your use case without explaining the use cases. Just the truth about what works and what does not work and how to make the call yourself. Based on over 600 projects and a decade ofwatching businesses navigate this decision.
Let Us Talk About What These Things Are
Ifwe strip away the hype here is what you are dealing with.
Prompt engineering means you are talking to the Artificial Intelligence better. That is literally it.
The model stays exactly as it came. You are just learning its language. Finding the words that make it do what you need. Writing instructions that actually work instead ofinstructions that sound smart.
Think about it like this. You hire someone who does not know your business yet. You could spend months training them on everything. Or you could just get really good at explaining what you need.
That is engineering. Better communication, same brain.
We do this for clients all the time. We write system prompts. We test phrasing. We add examples. We build chains where one instruction feeds into another. The model never changes. We just get surgical about how we talk to it.
Fine-tuning is retraining the model itself.
You are taking GPT or Claude or Llama. Teaching it your specific patterns. The weights change. The model actually learns your terminology your logic, your style. After tuning it is a different model than it was before. More specialized. More yours.
Here is the catch. Fine-tuning does not magically give it new information. Ifyou train it on 2023 data and ask about 2024 it is clueless. You have taught it how to think, not what to know.
RAG is different entirely.
You do not touch the model. You build a system that feeds it information on demand. Someone asks a question the system searches your documents grabs the chunks hands them to the model and says answer this based on what you just read.
Open-book test versus closed-book test. Fine-tuning is cramming everything into your head.
RAG is showing up with all your notes.
The problem is everyone treats these like they are versions ofthe same thing.
They are not.
They are tools for different jobs.
When Prompt Engineering Actually Solves It
I had a SaaS client call last year. They said we need to tune a model for customer feedback summaries. Our feedback is really specific.
No you do not.
We built the thing with prompts in a few weeks. Why. Because GPT-4 already knows how to summarize text. They did not need it to learn anything new. They needed it to follow their format and focus on their categories.
So we wrote a good system prompt. We gave it examples. We specified the structure.
Done.
Still using it today with barely any changes.
This works when the base model can already do the task. You just need it done your way. Specific format, focus, specific output structure. You are not teaching it new tricks. You are directing the tricks it already knows.
The task is straightforward. Summarization. Classification. Simple Q and A. Content generation.
Things that do not require specialized reasoning.
You need to move fast. Prompts update instantly. No training runs. No deployment ceremonies.
You test it, it works, it is live.
Money is tight. Prompt engineering is cheap. API costs plus dev time. That is it.
You do not have training data. You cannot fine-tune without examples. But prompts. You just need instructions.
This breaks when your domain has terminology the model does not understand. We had a client try prompt engineering for contract analysis. The model kept missing nuances because it did not deeply understand precedent.
No amount ofprompting fixed that.
You need consistency across thousands of outputs. Prompts have variance. For healthcare patient communication that variance was unacceptable. Every message needed to sound like their head nurse. We fine-tuned. The task requires reasoning about information the model was never trained on. Prompts cannot manufacture knowledge that does not exist.
When Fine-Tuning Is Actually Worth It
Fine-tuning costs money.
Time. Engineering expertise. Ongoing retraining because models drift and use cases evolve.
So when do you do it anyway.
We fine-tuned for a fintech client doing fraud detection. They needed the Artificial Intelligence to recognize specific patterns. Red flags in transaction descriptions. Relationships between account behaviors. Risk logic unique to their business.
They had thousands oflabeled transactions from their fraud team.
We took Llama 3. We trained it on their data. We deployed it.
The model got scary good at thinking like their fraud analysts. Catching patterns specific to their customer base that no generic model would recognize.
Could prompts work. Maybe. But they would be huge fragile inconsistent. RAG would not help because this is not about retrieving information. It is about reasoning with domain-specific logic.
Fine-tuning makes sense when you have a domain where the base model does not naturally think the way you need. Medical diagnosis. Legal analysis. Scientific research. Industry-specific workflows. The model needs to reason differently, not just follow instructions differently.
Output consistency matters more than flexibility. Specific writing voice. Particular format. Exact level ofdetail. Fine-tuning bakes that into the model.
You have the training data. Non-negotiable. Hundreds ofhigh-quality examples minimum.
Thousands is better.
The task is complex reasoning, not knowledge retrieval. Subtle classifications. Multi-factor decisions. Deep domain analysis.
You can afford the maintenance. Models need retraining. Your business evolves. Edge cases emerge. Budget for ongoing work.
Latency matters. Tuned models are just models. One call, one response. RAG has to retrieve first.
That adds time.
Fine-tuning fails at staying current. Ifyou trained on 2025 data it does not know 2026 events unless you retrain. Time-sensitive information needs RAG.
Handling the unexpected. The model learned from your examples. New situations might confuse it. You need engineering or RAG for novelty.
Most business use cases frankly. I have watched many companies spend months on custom Artificial Intelligence development only to realize prompts would have worked.
Do not be impressive. Be effective.
When RAG Actually Solves the Problem
RAG changed the game for knowledge-based Artificial Intelligence.
Before RAG ifyou wanted Artificial Intelligence to answer questions about company documentation your options sucked. Cram everything into prompts or fine-tune on your docs.
RAG fixed it. Elegantly.
We built one for an enterprise client with years ofdocumentation. Compliance guides, HR policies, technical specs, project histories. Thousands ofdocuments. Employees needed to ask questions and get answers with sources.
How it works. Someone asks what is our remote work policy for contractors.
The system searches the document database. Finds policy docs. Reads the sections. Generates an answer based on what those documents say.
Policy changes tomorrow. Update the database. No retraining. No prompt rewrites.
RAG works when you need Artificial Intelligence to know things it was not trained on. Company knowledge bases. Product docs. Research papers. Customer data. Historical records. The model needs access to information that did not exist during training.
That information changes constantly. Policies update. Products launch. Regulations change.
RAG keeps responses current by updating the database.
Citations and sources matter. RAG tells you where information came from. Critical for healthcare, compliance. Anywhere accuracy is existential.
You have unstructured data. Documents, emails, transcripts, reports. RAG handles it directly.
Fine-tuning needs structured examples.
Hallucination is unacceptable. RAG pulls real text from your database. The Artificial Intelligence reads and summarizes actual documents instead ofmaking things up.
The use case is information retrieval. Q and A systems. Research assistants. Document analysis.
Knowledge management. Tasks where the answer lives somewhere in your data.
RAG struggles with tasks that are not about retrieving information. Creative writing. Code generation. Formatting. There is nothing to retrieve. Use prompts or fine-tuning.
Architectural complexity. You need a vector database. Good chunking strategies. Logic for when information spans documents.
Not trivial.
Retrieval failures. Ifyour documents do not contain the answer the system might retrieve irrelevant chunks and generate nonsense. We have built fallback logic for this.
Speed. That retrieval step takes time. For some applications latency is a dealbreaker.
The Mistakes That Kill Projects
I have seen people try every way to mess up their artificial intelligence projects.
They choose their approach based on what sounds cool.
I saw a startup waste their budget on fine-tuning their model because their investor asked ifthey had fine-tuned anything not because they actually needed it but because it sounded good in meetings.
The tuned model did not work as well as GPT-4 with decent prompts so they got rid ofit.
You should choose your approach based on what solves your problem not what impresses people.
People often do not appreciate the importance ofengineering.
Developers do this all the time. They try one prompt it does not work perfectly. They immediately think they need to fine-tune their model.
Prompt engineering is a skill that takes time to develop.
We have spent weeks optimizing prompts and gotten massive improvements. You should try different prompts before deciding that prompts will not work. Fine-tuning a model without data is another common mistake.
You need hundreds ofexamples at the least and thousands is even better.
I have had clients come to me wanting to tune their model with limited examples but it is not enough. The model overfits and performs badly on anything outside the training set and they end up wasting their money.
If you do not have data you should do something else.
Building a Retrieval Augmented Generation system when you do not have retrieval needs is also a mistake.
One client wanted an artificial intelligence system to write marketing emails so we built a RAG system that pulled from emails.
But writing style is not a retrieval problem. Fine-tuning the model would have learned their brand voice better so they had to rebuild the system months later.
Ignoring maintenance is another mistake people make.
Fine-tuning and RAG need ongoing work, such as retraining the model and updating the database.
One client built a RAG system but did not budget for maintenance so later on many documents were outdated and the system gave wrong answers.
People often think that these approaches are mutually exclusive. You can combine them.
We have clients with RAG systems that use engineered prompts and tuned models that incorporate RAG for current information.
You should not force one technique to do everything.
For example we had a healthcare client who used a tuned model for medical reasoning and a RAG system for current drug information.
The tuned model understood medical logic and the RAG system kept it updated on new medications.
Together they worked excellently.
How We Actually Decide
When clients come to us we define the task precisely.
We do not say “we want intelligence for customer support”. That is too vague.
Instead we say “we want artificial intelligence to read support tickets classify them by category extract information and draft initial responses”.
Now we can evaluate approaches.
We test ifthe base model can do the task.
We literally test GPT-4 or Claude with a prompt. Ifit works reasonably well prompt engineering is probably enough and we just need to refine and add structure.
We identify what is missing. Ifthe model lacks domain knowledge we use tuning or RAG.
If it lacks current information we use RAG.
If it does not follow the required format we use engineering.
If it does not reason the way we need we use tuning.
We check our data situation. Ifwe have training examples fine-tuning is possible.
If we have documents or knowledge bases RAG is possible.
If we have neither prompt engineering is our only option without creating data from scratch.
We consider constraints. If we have a timeline prompt engineering is the fastest.
If we have a budget prompt engineering is the cheapest.
If we need machine learning engineers fine-tuning needs them.
If we need infrastructure RAG needs a vector database.
We prototype the simplest approach first.
We always start with engineering. Ifit works we are done.
If it does not we move to tuning or RAG based on what is failing.
We do not skip to the complex solution. We have had clients who were convinced they needed tuning but we built a prompt prototype quickly and it worked so the project was done and they saved significant time and money.
Using Multiple Approaches Together
The best systems we have built use multiple techniques.
For example an enterprise client needed an intelligence assistant for sales. It had to answer product questions using RAG write emails in the company voice using fine-tuning and format emails per templates using prompt engineering.
We combined all three approaches. RAG retrieves product information and pricing the fine-tuned model writes in their brand voice and understands their sales methodology and prompt engineering ensures proper structure and calls-to-action.
Each piece handles what it is good at.
Another example is a client who needed contract analysis. We fine-tuned the model on legal reasoning and their contract types added RAG to reference past contracts and precedents and used prompt engineering to structure output into their required report format.
This is how you build production intelligence that works at scale. You do not pick one technique and force it to do everything you architect a system where each component handles its strength.
Getting Started Without Overthinking It
Ifyou are doing engineering you should start simple. Describe the task in plain English test it
and then add structure, examples and constraints iteratively.
You should use version control for everything. We use Git because rolling back to versions is common.
You should test edge cases early. Weird input, ambiguous questions, offensive content. And build prompts that handle that.
You should use prompt chaining for complex tasks. One prompt extracts information another analyzes it and another formats output.
Ifyou are fine-tuning you should prepare your data first. This is most ofthe work.
You should clean it format it consistently and remove bad examples.
Your model is only as good as your training data.
You should fine-tune on a subset first and see ifit is working before processing thousands of examples.
You should evaluate rigorously, do not just check ifthe outputs look good test on held-out data and measure performance metrics.
You should budget for iteration. Your first tuned model will not be perfect and you will need to adjust hyperparameters add data and fix issues.
Ifyou are building a RAG system you should design your chunking strategy carefully. How do you split documents by paragraph, section or token count?
This matters enormously for retrieval quality.
You should choose your embedding model thoughtfully, different embeddings work better for different content types so test options.
You should build good metadata. Store document sources, dates, authors and categories because you need this for filtering and citation.
You should implement hybrid search. Combine vector similarity with keyword search for better results. You should handle retrieval failures gracefully. What happens when no relevant documents exist, do not let the model hallucinate, say “I do not have information about that”.
FAQ
The answer is that most chatbots use prompt engineering, which is fine for simple Q&A but breaks down with complex use cases.
What we are talking about here with prompt engineering vs fine-tuning vs RAG builds intelligence that truly understands your domain accesses your specific data and performs
specialized tasks. The difference between a generic chatbot template and custom artificial intelligence built for your business.
The answer is that the bare minimum is a few hundred quality examples but honestly we want a thousand or more for production. We have done projects with smaller datasets but the performance was marginal and more data means a better model. Ifyou do not have enough examples you should consider prompt engineering or RAG.
The answer is yes we do this all the time. Tune for domain reasoning and style and then wrap it in RAG for current information access it works great together you just need to architect it properly from the start so you are not rebuilding everything.
The answer is engineering by far. We have deployed prompt systems in under two weeks RAG takes longer depending on data complexity and fine-tuning takes even longer with data prep, training, testing and deployment.
If speed matters you should start with prompts.
The answer is maybe not. Do not let competition drive your technical decisions fine-tuning sounds impressive but it is not always better we have beaten fine-tuned models with good prompt engineering.
You should focus on what solves your problem not what sounds good in marketing.
The answer is that for engineering, no a good developer can handle it for RAG you need someone comfortable with vector databases and embeddings not necessarily a full machine learning engineer and for fine-tuning yes you really need machine learning expertise either hire someone or work with a partner who has that capability.
The answer is that you should define success metrics for customer support artificial intelligence maybe it is resolution rate and satisfaction scores for document analysis maybe it is accuracy and time savings.
You should measure against those metrics and get feedback from users. They will tell you what is working and what is not.
The answer is that you should use all three. The best artificial intelligence systems are hybrid, use fine-tuning for specialized reasoning RAG for information access and prompt engineering for task structure and formatting.
You should design your architecture to support techniques working together using prompt engineering vs fine-tuning vs RAG in combination.
Here Is What Actually Matters
What I wish someone had told me when we started building intelligence systems years ago is to not overthink this.
You should start simple try engineering first and ifit works you are done you just saved months and significant money.
Ifprompts are not enough figure out why. Lack ofknowledge build RAG, lack ofdomain-specific reasoning, fine-tune, both combine them.
These are not permanent decisions, artificial intelligence architecture evolves we have had clients start with prompt engineering migrate to RAG later when their knowledge base grew and add fine-tuning when expanding into a new market.
That is normal.
The goal is not to pick the most advanced technique the goal is to build artificial intelligence that solves your business problem effectively reliably and sustainably.
We have seen many companies burn budgets on overengineered solutions and get stuck with underperforming artificial intelligence because they went too simple.
The right answer is somewhere in the middle, specific to your use case your data and your constraints.
Ifyou are still not sure which approach fits your situation you should talk to people who have built these systems before walk through your use case and get an assessment.
We work with clients all the time using prompt engineering vs fine-tuning vs RAG frameworks.
Sometimes we tell them they do not need custom Artificial Intelligence development at all. Sometimes we say they should start small with prompts. Sometimes we plan out a RAG architecture or a fine-tuning roadmap for them.
The worst thing people can do is guess and hope they are right.
People can book a free discovery call with our team to get started.